For more than two decades, school systems in the US and around the world have introduced new accountability and incentive systems for public school educators that rely of the test scores of students as performance signals for educators. There is now a large empirical body of evidence on the effects of these assessment-based accountability and performance pay systems (Cunha and Heckman 2008).
Existing systems often suffer from two design flaws: They rely on performance targets or standards that are vulnerable to manipulation, and they use exams that can be easily compared to past formats in ways that encourage coaching or teaching to the test (see Neal 2011).
Most accountability systems employ performance targets that policymakers define using the units of a test-score scale associated with a particular assessment system. Thus, educators receive rewards or escape punishments if some statistic that summarises the performance of their students meets a fixed target. For example, the No Child Left Behind Act (2001) includes targets for the number of students who reach proficiency standards in each school and in subpopulations within schools, and schools face possible sanctions if their students do not reach these targets.
Targets are problematic for several reasons. To begin, policymakers require detailed information about the capacities of each student and each teacher in order to set efficient targets. Further, because teaching techniques and pedagogical resources evolve over time, the rates of achievement growth that one expects from particular types of students, when their teachers teach well, should evolve over time, and it is difficult to imagine how education officials can predict the evolution of these pedagogical frontiers ex ante.
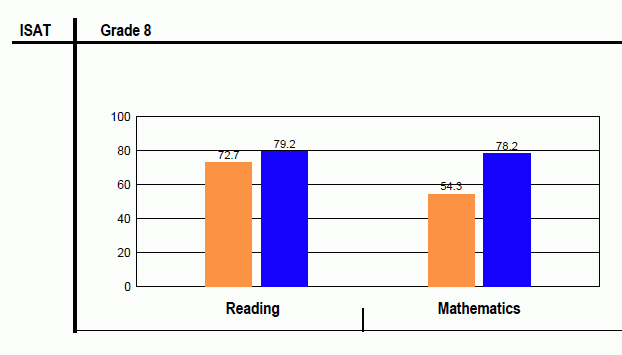
In addition, when education officials express achievement targets in units derived from psychometric scales that are the creation of researchers, the targets are often manipulable. Figure 1 presents proficiency rates for eighth graders in Illinois under No Child Left Behind (NCLB). In most years, there were small changes in state-wide proficiency rates, as we would expect even if schools were improving. However, between 2005 and 2006, state officials introduced a new assessment system and equated the proficiency scores for the two sets of tests. Note that in one year, the proficiency rate among eighth-grade mathematics students rose from 54% to 78%. There are two possible explanations for such a result. Eighth-grade teachers in Illinois adopted some change in education practice in 2006 that created enormous proficiency gains in one year, or state officials allowed the new test to be equated with the old test in a manner that effectively lowered the proficiency standard.
Figure 1. Changes in math proficiency in IL: Introduction of a new assessment system
Scaling assessments and equating scales on different assessments are quite technical tasks. Because it is difficult to correctly maintain the integrity of psychometric scales when one is trying to do so, it is also quite difficult for the public to detect deliberate attempts to lower effective standards by making assessments easier over time without properly adjusting the scoring procedures (Cronin et al 2007).
The use of test scores from standard assessment systems to create performance metrics for educators not only creates concerns about direct manipulations of test score scales that may in turn contaminate performance metrics for educators. The use of results from these assessment systems also creates concerns about hidden actions that educators may take to improve student tests scores without generating a commensurate improvement in subject mastery.
Modern assessment systems are designed to produce consistently scaled scores over time because education officials want to know whether fifth graders in 2011 actually performed better or worse in maths than fifth graders in 2005. This need for consistent scaling creates a need to form links between assessments given in different years, and test developers typically create these links by repeating items and making sure that all assessments follow a common format. However, repeated questions and formats make each test predictable, and this predictability implies that teachers have an incentive to coach students concerning the answers to specific questions or strategies for answering specific types of questions. These test-prep behaviours are socially harmful for two reasons. They crowd out better uses of class time, and these behaviours artificially inflate student test scores and thus contaminate public information about secular trends in student achievement (Koretz 2002, Stecher 2002, Holmstrom and Milgrom 1991).
Education officials can improve both accountability systems and the systems used to track secular trends in achievement by developing separate measurement systems for these two objectives. Assume that policymakers can develop assessment systems such that each yearly assessment covers the curriculum, but each yearly assessment also contains no questions from previous assessments. Further, assume that the formats for the assessments in this new series vary randomly from year to year. Such a system would remove many of the incentives for coaching and test-prep activities that plague existing accountability systems, but it would not provide reliable information about trends in student achievement since it would be difficult if not impossible to place results from different years on a common scale. However, policymakers can implement effective assessment-based accountability without scale scores while using a separate no-stakes assessment system to produce consistently scaled information about achievement trends.
Pay for Percentile
In Barlevy and Neal (forthcoming), we describe an assessment-based incentive system for educators built around educator performance metrics that are invariant to the scaling of student assessments. These metrics are also relative-performance metrics because they do not express educator performance relative to a statistical target but relative to the performance of other educators that form an appropriate comparison set.
We call this scheme Pay for Percentile. It is built around a performance metric called the Percentile Performance Index (PPI). The following algorithm describes how one might calculate PPI scores for teams of teachers that work together to teach one class, eg fifth-grade maths, in the same school.
- Step One: Consider all students in a large school district or state who are taking the same class, eg fifth-grade maths. Place each student in a comparison set with students who are similar in terms of their expected achievement given their past academic performance, their demographic characteristics, and the characteristics of other students in their school or classroom.
- Step Two: At the end of the year, when the fifth-grade maths assessment results are reported, rank all students in each comparison set based on their end–of-year scores, and assign each student a percentile equal to the fraction of students in her comparison set who performed the same or worse.
- Step Three: Overall the students in a given school who are taking a particular subject, eg fifth-grade maths, form the average of their percentile scores. This average is the PPI score for the team of fifth-grade maths teachers at this school. It reflects how often students in a given course in a given school perform as well or better than comparable students elsewhere.
We show that it may be possible to elicit effective teaching by paying teams of educators performance bonuses that are proportional to PPI metrics. Further, our basic result holds in the presence of instructional spillovers, peer effects, and heterogeneity in rates of student learning within classrooms.
A large literature in economics explores how properly seeded contests can be used to create incentive systems. Pay for Percentile generalises these results to a setting where workers (educators) produce many different outputs (achievement growth for many students) simultaneously by allocating time among several different tasks (lecturing, tutoring, lesson planning, etc). Because all contests are properly seeded, teachers respond by allocating efficient effort to all tasks that foster achievement for the set of students in a given class.
Pay for Percentile uses seeded competition to create performance metrics. PPI scores implicitly summarise the outcomes of many different simultaneous contests among students, and every contest that one fifth-grade maths team wins is a contest that another team lost. By construction, PPI scores do not tell policymakers how often students in a given school or classroom reached some pre-determined achievement target. Rather, PPI scores tell policymakers how often students in a given class or school outperformed students in other schools that began the year as their academic peers.
Because every contest between matched students in different schools must have one winner and one loser by construction, this approach also eliminates the Lake Wobegon effects that plague many accountability and performance pay systems. Neal (2011) argues that often, in target-based systems that permit the possibility that all educators can be judged satisfactory, almost all educators are deemed satisfactory whether they deserve to be or not.
As we note above, since Pay for Percentile involves assessments that avoid repeated items and predictable formats, these assessments will not provide much information about secular trends in student achievement. However, if policymakers use a separate no-stakes assessment system to measure student achievement, they eliminate incentives for educators to engage in the "teaching to the test" behaviours that often inflate reported achievement trends derived from high-stakes testing systems.
This approach may seem bizarre to many in the education testing and policy community. To many, it seems intuitive that, if educators should be held accountable for what their students learn, education officials should create measures of student achievement and educator performance using a single assessment system. However, the job of placing student assessment results on modern psychometric scales does not need to be and should not be part of the process of building accountability and incentive systems for educators. Whenever policymakers insist that these tasks be intertwined, they are only guaranteeing that education officials will perform both tasks poorly.
The views expressed here do not reflect those of the Federal Reserve Bank of Chicago or the Federal Reserve System.
Derek Neal thanks the Searle Freedom Trust for research support. Neal also thanks Lindy and Michael Keiser for research support through a gift to the University of Chicago’s Committee on Education.
References
Barlevy, Gadi and Derek Neal (2011), “Pay for Percentile”, American Economic Review, forthcoming.
Cunha, Flavio and James Heckman (2008), "Formulating, Identifying and Estimating the Technology of Cognitive and Noncognitive Skill Formation", Journal of Human Resources,43:739-780.
Cronin, John, Michael Dahlin, Deborah Adkins, and G. Gage Kingsbury (2007), "The Proficiency Illusion", Thomas B Fordham Institute, October 2007.
Holmstrom, Bengt and Paul Milgrom (1991), “Multitask Principal-Agent Analyses: Incentive Contracts, Asset Ownership and Job Design", Journal of Law, Economics and Organization,7:24-52.
Koretz, Daniel M (2002), “Limitations in the Use of Achievement Tests as Measures of Educators' Productivity”, Journal of Human Resources,37(4):752-777.
Neal, Derek (2011), "Providing Incentives for Educators", in Eric Hanushek, Steve Machin, and Ludger Woessmann (eds.), Handbook of Economics of Education, Vol 4.
Stecher, Brian M (2002), "Consequences of Large-Scale, High-Stakes Testing on School and Classroom Practice", in Laura S Hamilton, Brian M Stecher, and Stephen P Klein (ed.), Making Sense of Test-Based Accountability in Education, National Science Foundation.